The Real Problem
真正的問題
The obvious problem was volume: 6 platforms (LinkedIn, CakeResume, Yourator, 104, Meet.jobs, company career pages), different formats, different update cadences. But the real problem was signal. Most of my time was spent on roles that weren't a good fit. I had no systematic way to know: which roles actually match what I'm good at? Where should I invest my limited time?
在 6+ 平台間追蹤機會意味著在瀏覽器分頁間切換、搞不清楚哪些已經看過、錯過時效性項目。每個平台的格式不同、更新頻率不同,也沒辦法交叉比對訊號。我需要一個能聚合、分析、並凸顯重點的系統。
The System
系統
I built a triage and prioritization system. It aggregates roles from 6 sources daily, uses AI to score each one against my actual experience, and surfaces the ones worth my time. The dashboard gives me a morning brief (what's new, what needs follow-up), a pipeline view (where is each opportunity), and a career coach (interview prep from my own stories). The result: I went from spending most of my time browsing to spending most of my time preparing for the right conversations.
我打造了一個自動化 pipeline,每日從 6+ 平台抓取資料,用 AI 評分與排序,透過本地 web dashboard 呈現所有內容。系統包含優化建議、跨訊號模式分析,以及自動化的 email 摘要。
How It Works
運作方式
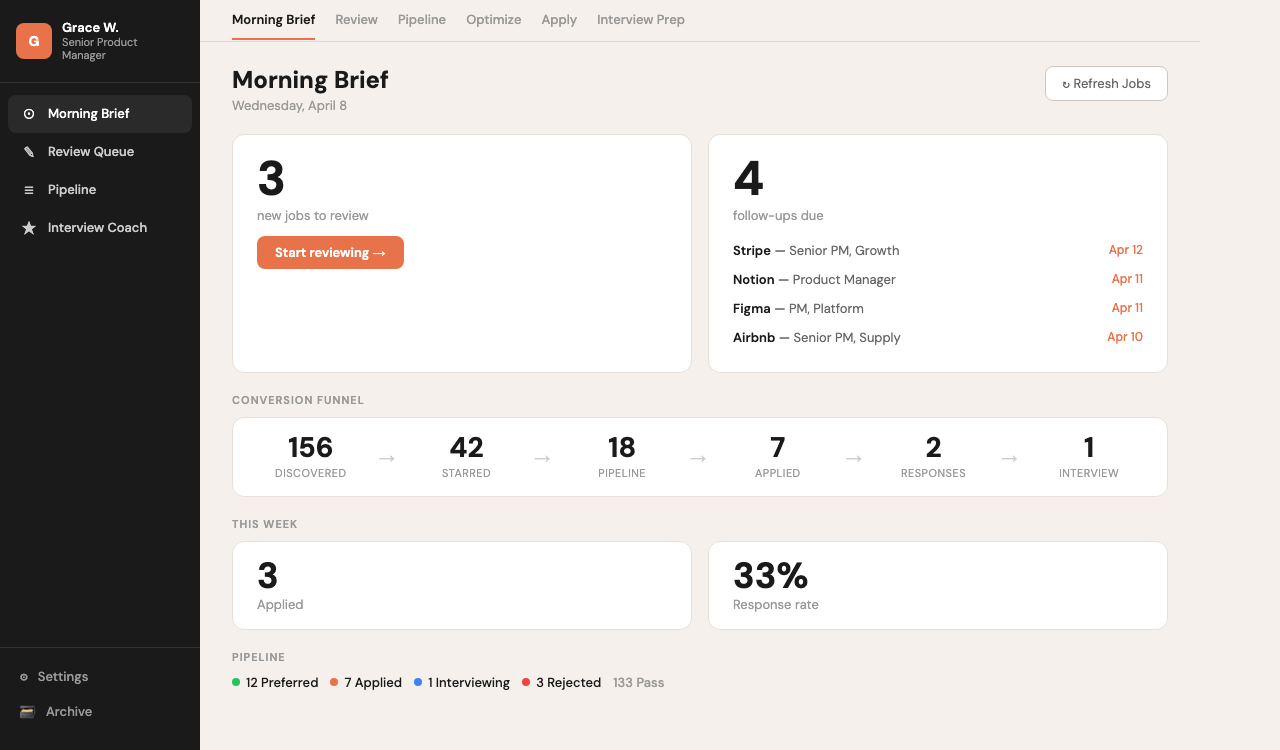
Morning Brief: daily triage with new matches, follow-ups due, and funnel stats
每日簡報:新配對、待追蹤、以及漏斗統計
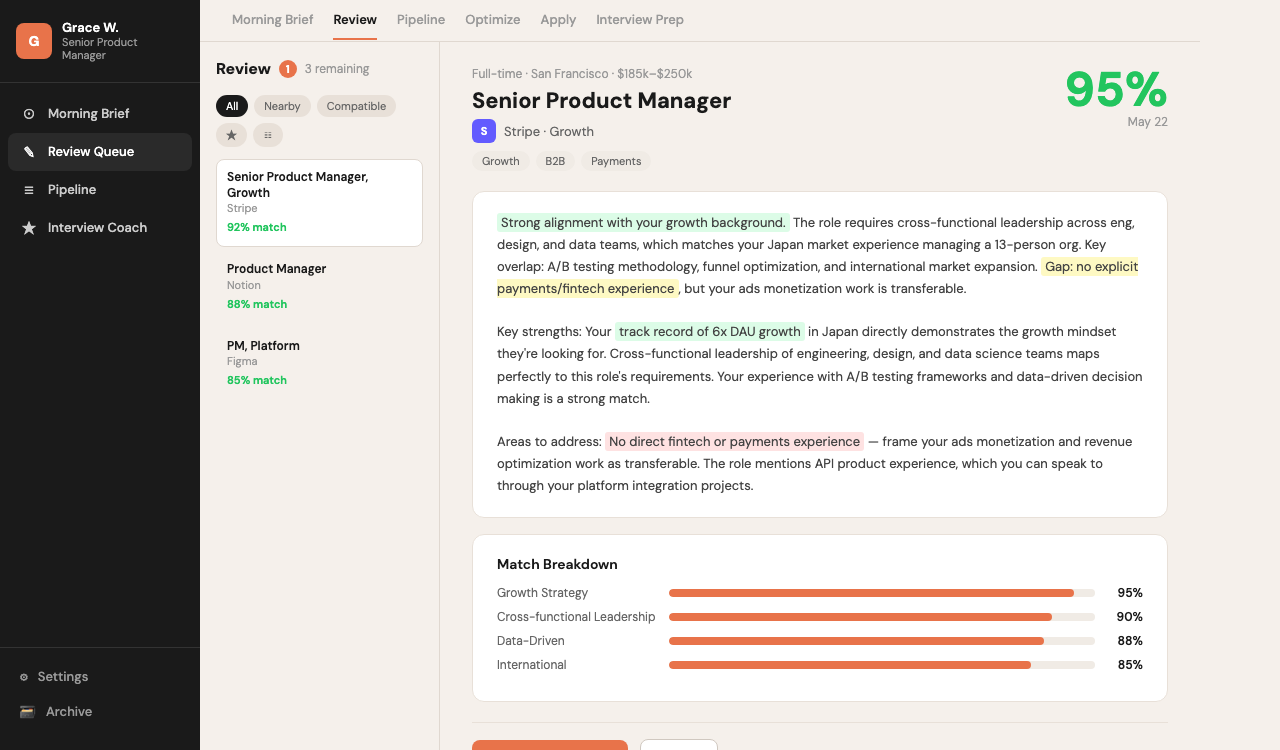
Review Queue: AI scores each role against your profile with match reasoning
審核佇列:AI 根據你的背景為每個職缺評分並說明原因
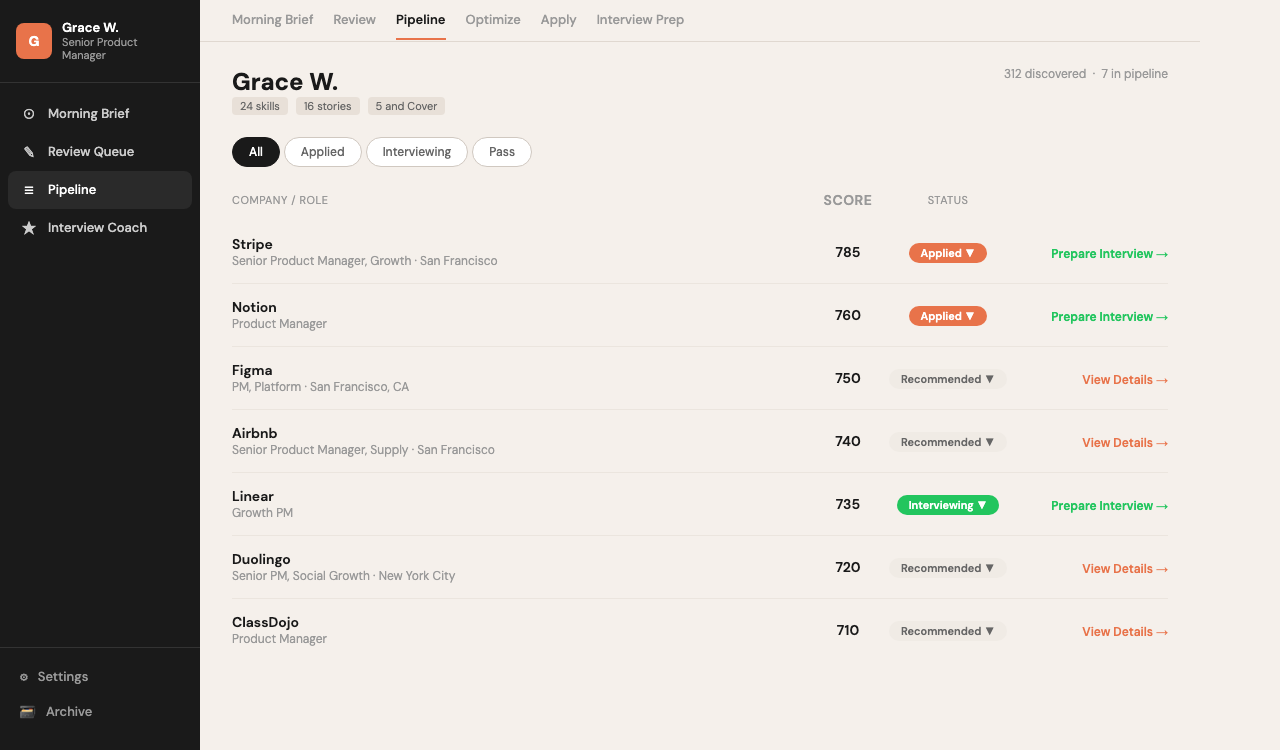
Pipeline: track every opportunity from discovery to interview with next actions
Pipeline:追蹤每個機會從發現到面試的進度與下一步
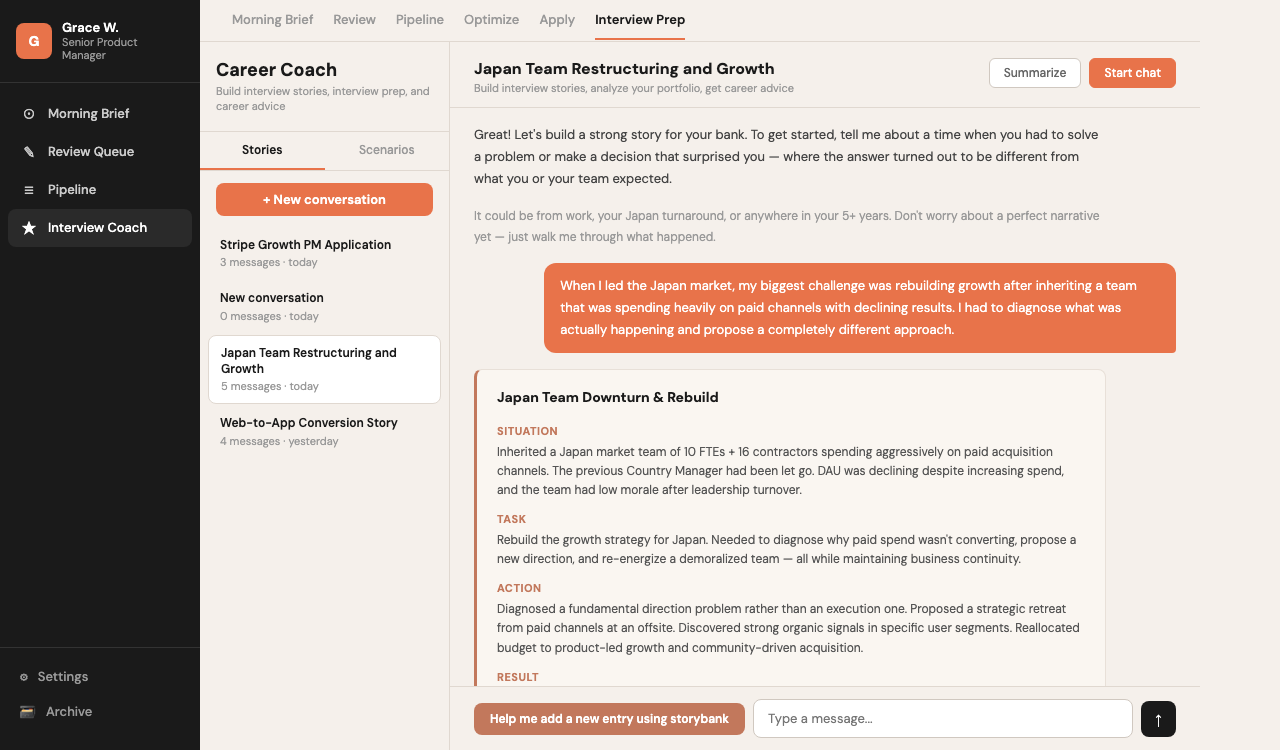
Career Coach: interview prep that builds STAR stories from your actual experience
Career Coach:根據你的實際經歷建構 STAR 故事的面試準備
Architecture
架構設計
6+ Platform
Scrapers
6+ 平台爬蟲
→
Data
Normalization
資料
規範化
→
AI Scoring
(Claude API)
AI 評分
(Claude API)
→
Dashboard +
Pipeline
Dashboard +
Pipeline
Key Decisions & Learnings
關鍵決策與學習
Why Playwright for Scraping?為什麼用 Playwright 做爬蟲?
— Most platforms require JavaScript rendering and authentication. Playwright handles both, plus provides screenshot capabilities for debugging. The headless browser approach also handles anti-bot protections better than raw HTTP requests. — 大多數平台需要 JavaScript 渲染和驗證。Playwright 兩者兼顧,還提供截圖功能方便除錯。無頭瀏覽器的方式也比原始 HTTP 請求更能應對反爬蟲機制。
AI Scoring FrameworkAI 評分框架
— Built a multi-criteria scoring system using Claude API that evaluates items across dimensions like relevance, quality, and timing. The framework is configurable — criteria and weights can be adjusted without code changes via a YAML config. — 用 Claude API 建立多維度評分系統,從相關性、品質、時效等面向評估項目。框架可配置——透過 YAML 設定檔即可調整評分標準和權重,無需改程式碼。
Local-First ArchitectureLocal-First 架構
— Deliberately kept everything local — no cloud database, no SaaS dependencies. Data stays on my machine, the dashboard runs on localhost, and the cron job handles scheduling. This keeps costs at zero and data private. — 刻意維持全本地架構——沒有雲端資料庫,不依賴 SaaS。資料留在本機,dashboard 在 localhost 運行,cron job 處理排程。成本歸零,資料也保有隱私。